Published
- 10 min read
LLM Zoomcamp Module 1: Introduction to LLMs and RAG
LLM Zoomcamp Module 1: Introduction to LLMs and RAG
Overview

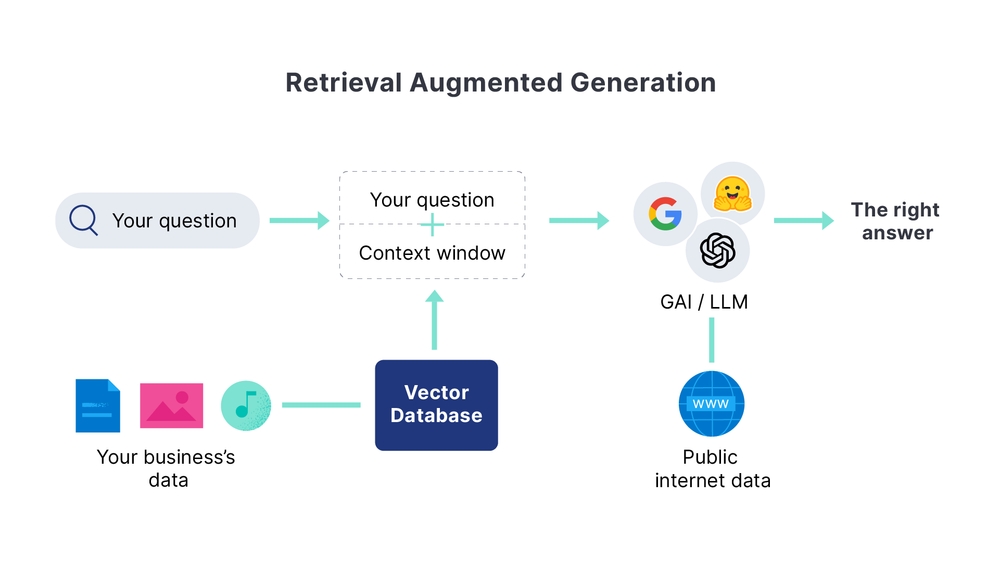
I Just completed Module 1 of the LLM Zoomcamp by DataTalks.Club, and wow - what a practical introduction to the world of Large Language Models! This wasn’t your typical theoretical course. We dove straight into building a real RAG (Retrieval-Augmented Generation) system from scratch.
What’s RAG and Why Should You Care?
Before jumping into the technical details, let me explain what RAG actually is. You know how ChatGPT sometimes makes stuff up (hallucinates)? RAG solves this by giving the LLM access to specific, reliable information before it generates an answer.
The idea is simple but powerful:
- Retrieve relevant information from a knowledge base
- This involves searching through your knowledge base (which could be vector databases, document stores, or other repositories) to find the most relevant pieces of information based on the user’s query. The quality of retrieval often depends on how well you’ve embedded and indexed your documents, and what similarity metrics you use.
- Augment the user’s question with this context
- This is where you take the user’s original question and enrich it with the context you’ve retrieved. This step is crucial because it provides the LLM with specific, relevant information it can use to generate a more accurate and grounded response.
- Generate an answer based on the retrieved information
- Finally, the LLM uses both the original question and the retrieved context to produce an answer that’s informed by your knowledge base rather than relying solely on its training data.
It's like giving the AI a cheat sheet before an exam.The Architecture We Built
Our RAG system had three main components:
1. Document Storage & Search (ElasticSearch)
We used ElasticSearch as our search engine to store and retrieve documents. The dataset? All the FAQ documents from DataTalks.Club courses - perfect for building a course assistant.
What is Elasticsearch?
Elasticsearch is a distributed, RESTful search and analytics engine built on Apache Lucene. It’s designed to handle large volumes of data and provide near real-time search capabilities. Think of it as Google for your application data – it can index documents, analyze text, and return relevant results in milliseconds.
Key Elasticsearch Concepts:
- Index: A collection of documents (like a database)
- Document: A JSON object containing your data
- Field: Individual properties within a document
- Query: Instructions for finding matching documents
- Score: Relevance ranking of search results
The multi-match query used for searching across multiple fields simultaneously. Instead of searching just one field, you can search across title, content, tags, and any other fields in your documents.
Field boosting allows you to assign different weights to different fields, making some fields more important than others in determining relevance scores.
Multi-Match Types: Focus on “best_fields”
Elasticsearch offers several multi-match types, each with different scoring behaviors:
- best_fields (Default)
The best_fields type finds documents where any field matches and uses the highest-scoring field to calculate the overall score.
When to use: When you want the best matching field to dominate the score, perfect for scenarios where a strong match in one field (like title) should rank higher than weak matches across multiple fields.
json{
"multi_match": {
"query": "How do copy a file to a Docker container?",
fields": ["question^4", "text"],
"type": "best_fields"
}
}most_fieldsCombines scores from all matching fields, favoring documents that match across multiple fields.cross_fieldsTreats all fields as one big field, useful when query terms might be split across different fields.phraseandphrase_prefixFor exact phrase matching across fields.
2. Retrieval System
The Retrieval System acts as the bridge between your user’s question and ElasticSearch.
When a user asks a question, this component:
- Processes the query: Takes the user’s natural language question and potentially reformulates or cleans it for better search performance
- Executes the search: Sends the query to ElasticSearch using appropriate search parameters (like match queries, filters, or more complex search strategies)
- Ranks and filters results: ElasticSearch returns multiple documents with relevance scores, and your retrieval system decides which ones are most relevant
- Extracts context: Pulls out the specific text chunks or passages from the retrieved documents that are most likely to contain the answer
- Formats for generation: Prepares the retrieved information in a format that can be effectively used by the LLM in the next step
The retrieval system essentially determines what information gets passed to the LLM, making it critical for answer quality.
When a user asks a question, we search through the indexed documents to find the
most relevant information. This becomes the "context" for our LLM.3. Generation (groq API)
Finally, we send both the user’s question and the retrieved context to an LLM (groq’s LLAMA models) to generate a comprehensive answer.
The Generation component uses the Groq API to create the final answer by:
- Combining context with query: Takes the user’s original question and the relevant context retrieved from ElasticSearch
- Prompt engineering: Structures this information into a well-formatted prompt that instructs the LLM how to generate a helpful response
- API call to Groq: Sends the augmented prompt to Groq’s fast inference API
- Response processing: Receives the generated answer and potentially post-processes it (formatting, validation, etc.)
- Grounded responses: The LLM generates answers based on the specific retrieved documents rather than just its general training knowledge
Let’s dive right in
Setting Up the Environment
First things first - getting ElasticSearch running locally:
docker run -it \
--rm \
--name elasticsearch \
-p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
docker.elastic.co/elasticsearch/elasticsearch:8.4.3Document Indexing
The course provided a JSON file with FAQ data from various DataTalks.Club courses. I had to:
- Parse the JSON documents
import json
with open('documents-llm.json', 'rt') as f_in:
docs_raw = json.load(f_in)
documents = []
for course_dict in docs_raw:
for doc in course_dict['documents']:
doc['course'] = course_dict['course']
documents.append(doc)- Create an ElasticSearch index with proper mappings
from elasticsearch import Elasticsearch
es_client = Elasticsearch('http://localhost:9200')
# Create index with custom settings
index_settings = {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"text": {"type": "text"},
"section": {"type": "text"},
"question": {"type": "text"},
"course": {"type": "keyword"}
}
}
}
index_name = "course-questions"- Ingest all documents into the search engine
Building the Search Function
The search function was where the magic happened. We used ElasticSearch’s multi-match query to search across multiple fields with different weights:
def elastic_search(query):
search_query = {
"size": 5,
"query": {
"bool": {
"must": {
"multi_match": {
"query": query,
"fields": ["question^3", "text", "section"],
"type": "best_fields"
}
},
"filter": {
"term": {
"course": "llm-zoomcamp"
}
}
}
}
}
response = es_client.search(index=index_name, body=search_query)
result_docs = []
for hit in response['hits']['hits']:
result_docs.append({
'source': hit['_source'],
'score': hit['_score']
})
return result_docsNotice the ^3 in "question^3" - this gives the question field 3x more weight than other fields. Smart!
Prompt Engineering
This was probably the most interesting part. We had to craft prompts that would:
- Provide clear context from retrieved documents
- Give the LLM specific instructions on how to respond
- Ensure the model stays grounded in the provided information
def build_prompt(query, search_results):
prompt_template = """
You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.
Use only the facts from the CONTEXT when answering the QUESTION.
QUESTION: {question}
CONTEXT:
{context}
""".strip()
context = ""
for doc in search_results:
context = context + f"section: {doc['section']}\nquestion: {doc['question']}\nanswer: {doc['text']}\n\n"
prompt = prompt_template.format(question=query, context=context).strip()
return promptPutting It All Together
We used a function to generate answer using groq’s LLAMA LLM with the given prompt context.
The final RAG function combined everything:
def llm(prompt):
response = client.chat.completions.create(
model="llama-3.3-70b-versatile",
messages=[
{
"role": "user",
"content": prompt
}
],
)
return response.choices[0].message.content
def rag(query):
# 1. Retrieve relevant documents
search_results = search(query)
# 2. Build prompt with context
prompt = build_prompt(query, search_results)
# 3. Generate answer using OpenAI
answer = llm(prompt)
return answerLet’s test our RAG implementation
- query = “How do copy a file to a Docker container?”
# Template for formatting each retrieved document as Q&A pairs
# This creates a consistent format for the LLM to understand the context
context_template = """
Q: {question}
A: {text}
""".strip()
# Initialize empty string to build the full context from all retrieved documents
context = ""
# Loop through all documents returned by ElasticSearch
for doc in result_docs:
context += context_template.format(question=doc['source']['question'],text=doc['source']['text'])+"\n\n"
# Main prompt template that instructs the LLM how to behave
# Sets role as teaching assistant and establishes rules for answering
prompt_template = """
You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.
Use only the facts from the CONTEXT when answering the QUESTION.
QUESTION: {question}
CONTEXT:
{context}
""".strip()
# Combine the user's question with all the retrieved context
# This creates the final prompt that will be sent to the LLM
prompt = prompt_template.format(question=query,context=context)
# Send the augmented prompt to the LLM via Groq API
# The LLM now has both the question and relevant context to generate an answer
response = client.chat.completions.create(
...
)
# Extract the generated answer from the API response
answer = response.choices[0].message.content
print(answer)This is the answer our model returns
To copy a file to a Docker container, you can use the `docker cp` command. The basic syntax is as follows:
`docker cp /path/to/local/file container_id:/path/in/container`
You can find the `container_id` by running the `docker ps` command.And it worked! The system would find relevant FAQ entries and generate coherent, accurate answers based on the course materials.
What is tiktoken?
Tiktoken is OpenAI’s tokenization library that converts text into tokens - the basic units that language models process. Understanding tokenization is crucial for RAG systems because:
- APIs charge by tokens
- Models have token limits
- Token count affects context window management
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-4o")This creates an encoder specifically for GPT-4o, which is important because:
- Different models use different tokenization schemes
- Token counts can vary between models
- Ensures accurate token counting for your specific model
Encoding and Analyzing Text
tokens = encoding.encode(prompt)
print(f"Number of tokens: {len(tokens)}")
print(f"Tokens: {tokens}")
print(f"Decoded tokens: {[encoding.decode([token]) for token in tokens]}")This code:
- Encodes your prompt into a list of token IDs (integers)
- Counts tokens - essential for staying within API limits
- Shows token IDs - the numerical representation the model sees
- Decodes each token - reveals how the text was split (words, parts of words, punctuation, etc.)
Number of tokens: 309
Tokens: [63842, 261, 4165, 14029, 29186, 13, 30985, 290, 150339, 4122, 402, 290, 31810, 8099, 591, 290, 40251, 786
...]
Decoded tokens: ["You're", ' a', ' course', ' teaching', ' assistant', '.', ' Answer', ' the', ' QUESTION', ' based'
...]Reverse Token Lookup
token_bytes = encoding.decode_single_token_bytes(63842)
token_text = token_bytes.decode('utf-8')This demonstrates:
- Single token decoding - takes a specific token ID (63842) and converts it back to text
- Byte-level handling - shows tiktoken works at the byte level before converting to UTF-8 text
token_textprints
"You're"Key Insights and Challenges
What Worked Well
- ElasticSearch’s multi-match queries were incredibly effective for finding relevant documents
- Prompt engineering made a huge difference in response quality
The “Aha!” Moments
- Realizing how much search quality affects the final answer - garbage in, garbage out
- Understanding that RAG isn’t just about fancy AI - it’s fundamentally about information retrieval
- Seeing how simple prompts can be more effective than complex ones
What’s Next?
Module 1 gave me a solid foundation, but there’s so much more to explore:
- Vector search instead of just text search---
This was honestly one of the most practical AI courses I’ve taken. Instead of just learning theory, I built something that actually works and could be deployed in the real world.
Resources
Building RAG systems is like being a librarian for an AI - you need to organize information well so the AI can find and use it effectively. The technical implementation is just one part; understanding your data and users’ needs is equally important.
Ready to dive deeper into the world of LLMs? The journey has just begun!